简介
前几天发了一个安装Robot Framework的文章,今天就说一下第一个小脚本,当你完全理解了这个小脚本之后就算入门了
安装配置编辑器
前几天安装了RIDE编辑器,但是这个编辑器不是那么好用,总会莫名其妙的出现一些问题,所以我们需要安装另外一个编辑器
我这里使用的编辑器是vscod,这个是微软官方出品的,界面友好,支持中文,支持很多拓展插件
下载编辑器
直接百多vscode或者是点击下方官网地址进行下载
官网地址:https://code.visualstudio.com/
点击图中的【Download for Windows】下载
安装编辑器
打开下载文件夹
双击刚刚下载的安装包打开
点击【下一步】
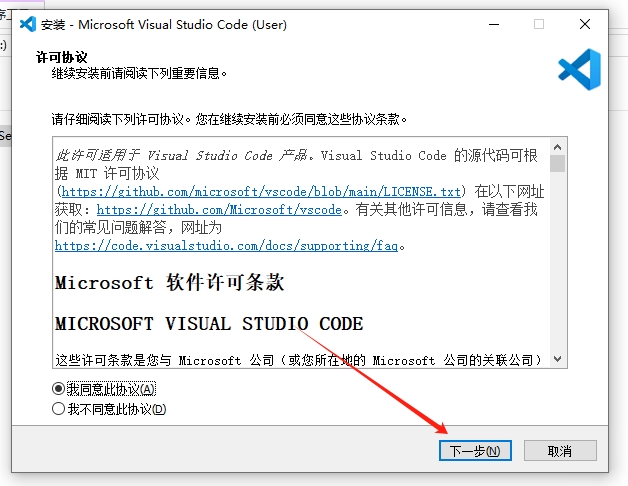
选择安装路径,我这里是虚拟机只有一个C盘,所以默认,大家可以根据自己的喜好自行选择,选择好之后点击【下一步】
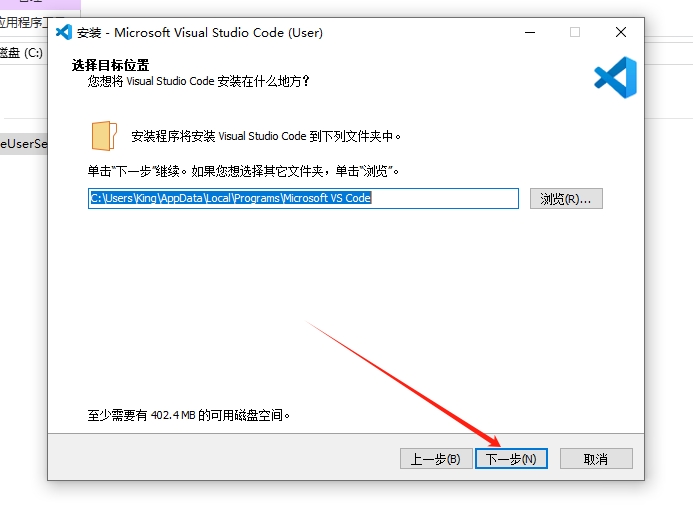
默认选择,点击【下一步】
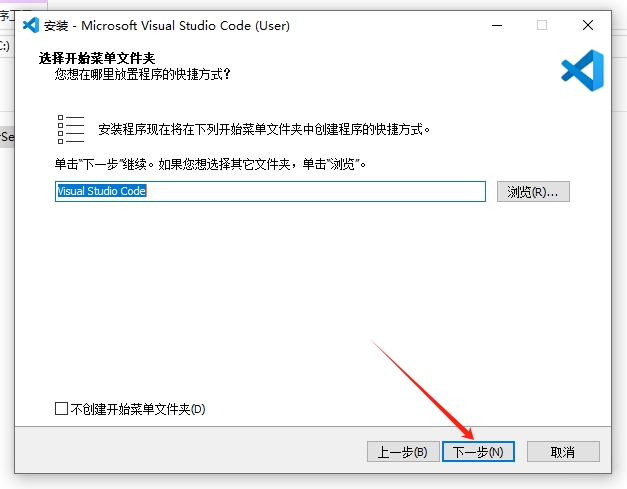
继续默认,点击【下一步】
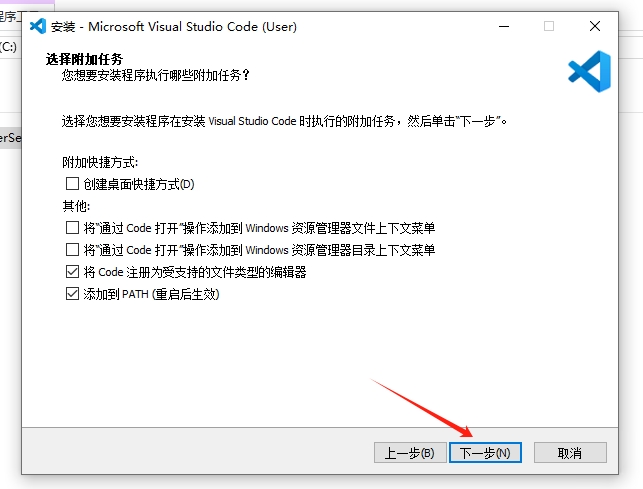
点击【安装】
点击【完成】
设置编辑器语言为中文
打开后,发现编辑器是英文的,如果你不需要改中文的话可以跳过这个步骤
点击左边的积木图标
在上方的搜索栏搜索“chinese”
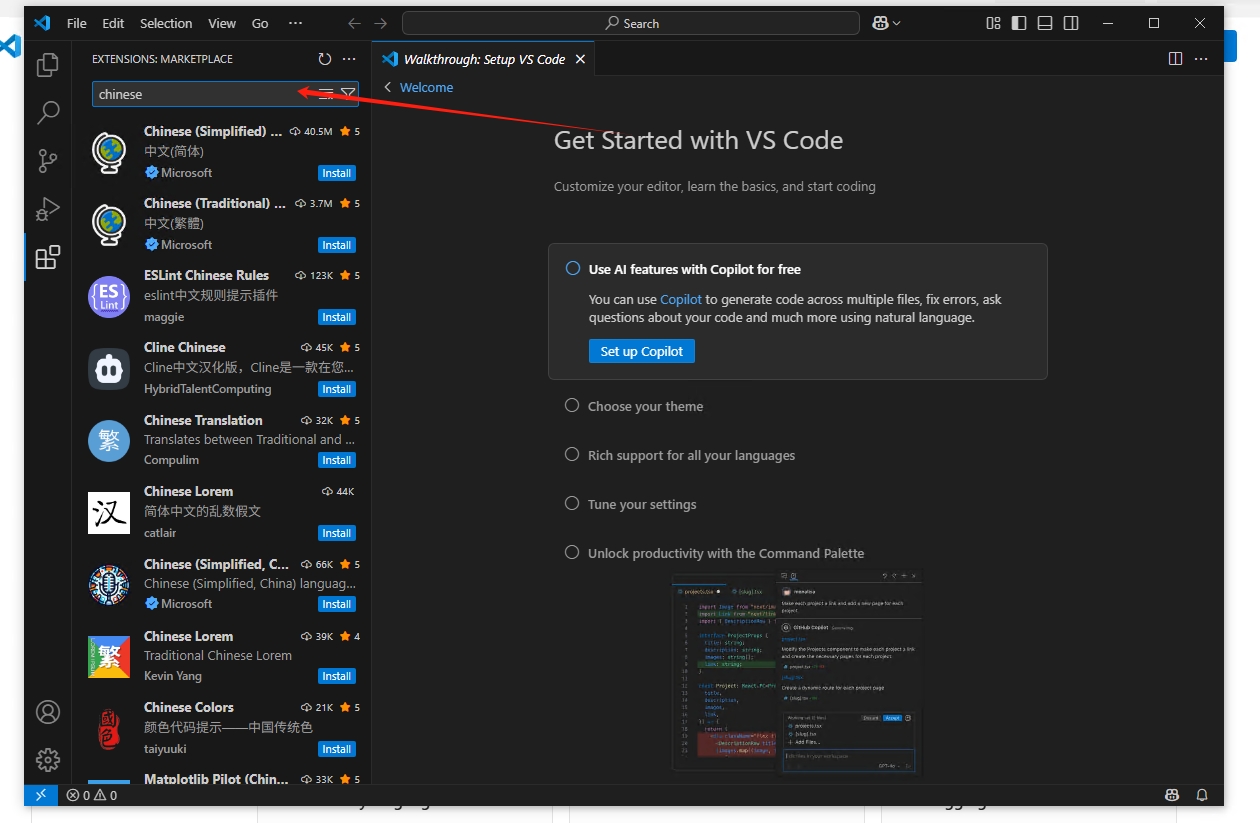
点击【install】安装
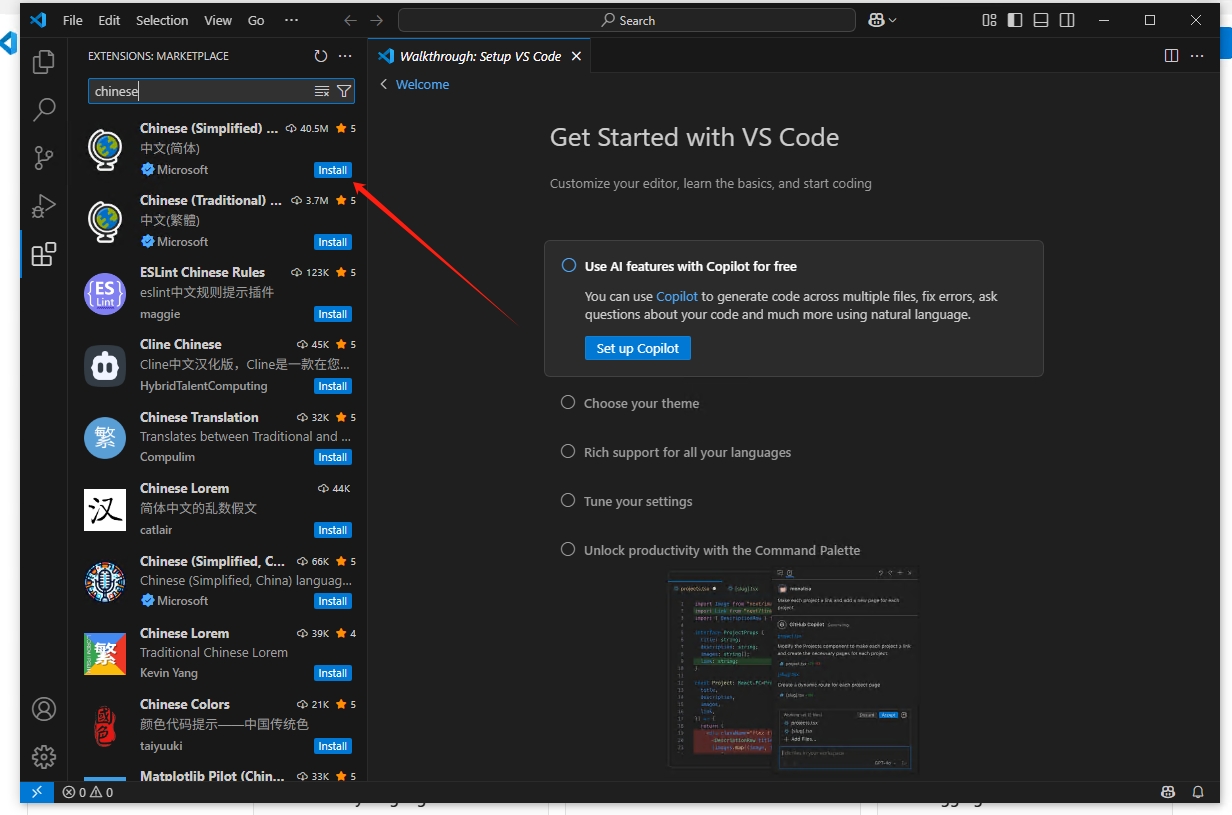
安装完成后点击右下角的【Change Language and Restart】重启编辑器
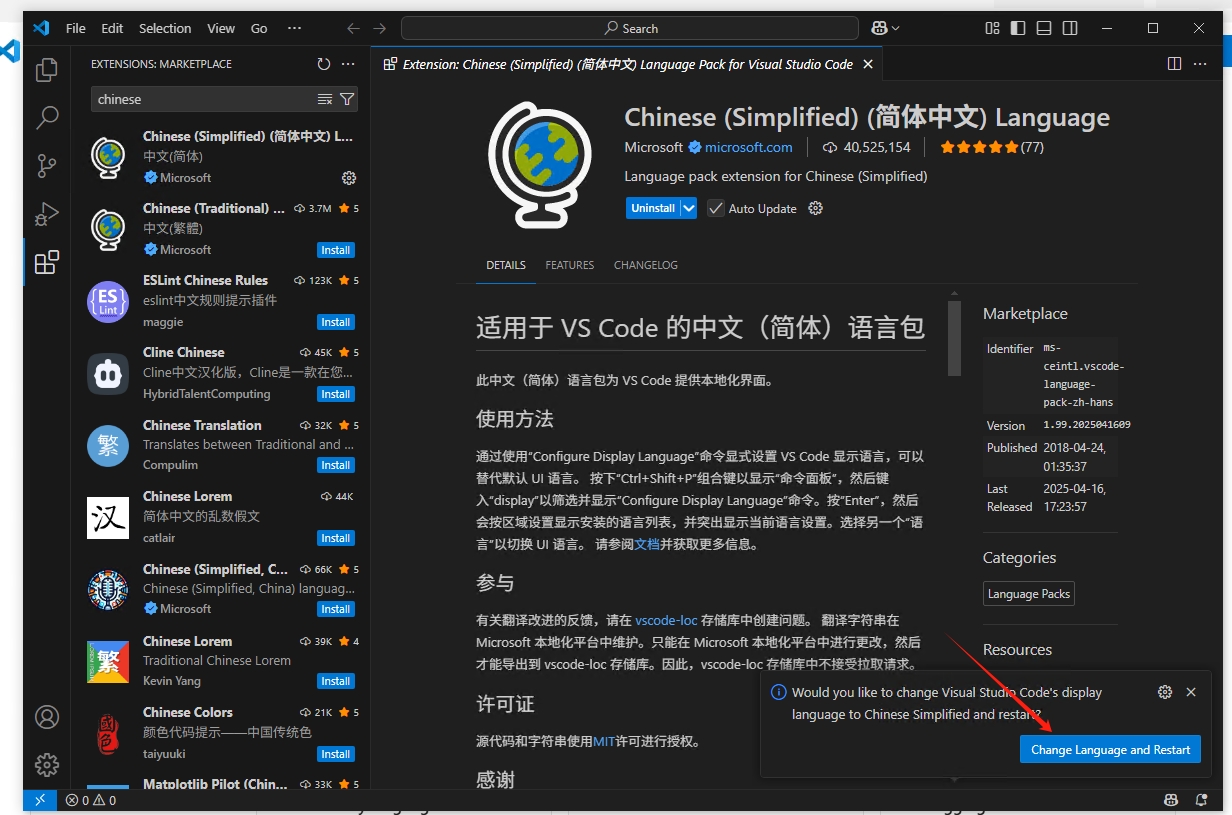
重启编辑器后就可以看到编辑器的语言变成中文了
安装python支持插件
继续点击右边的小积木图标
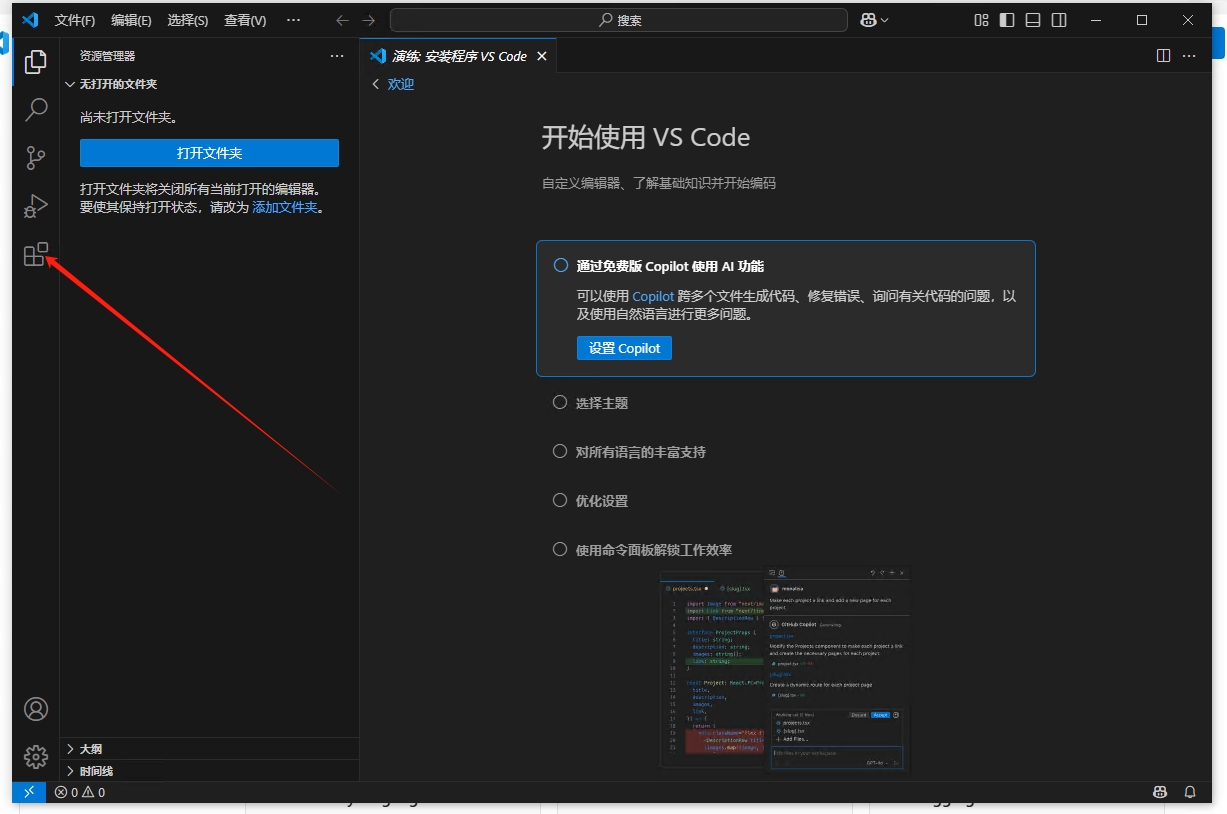
搜索“python”
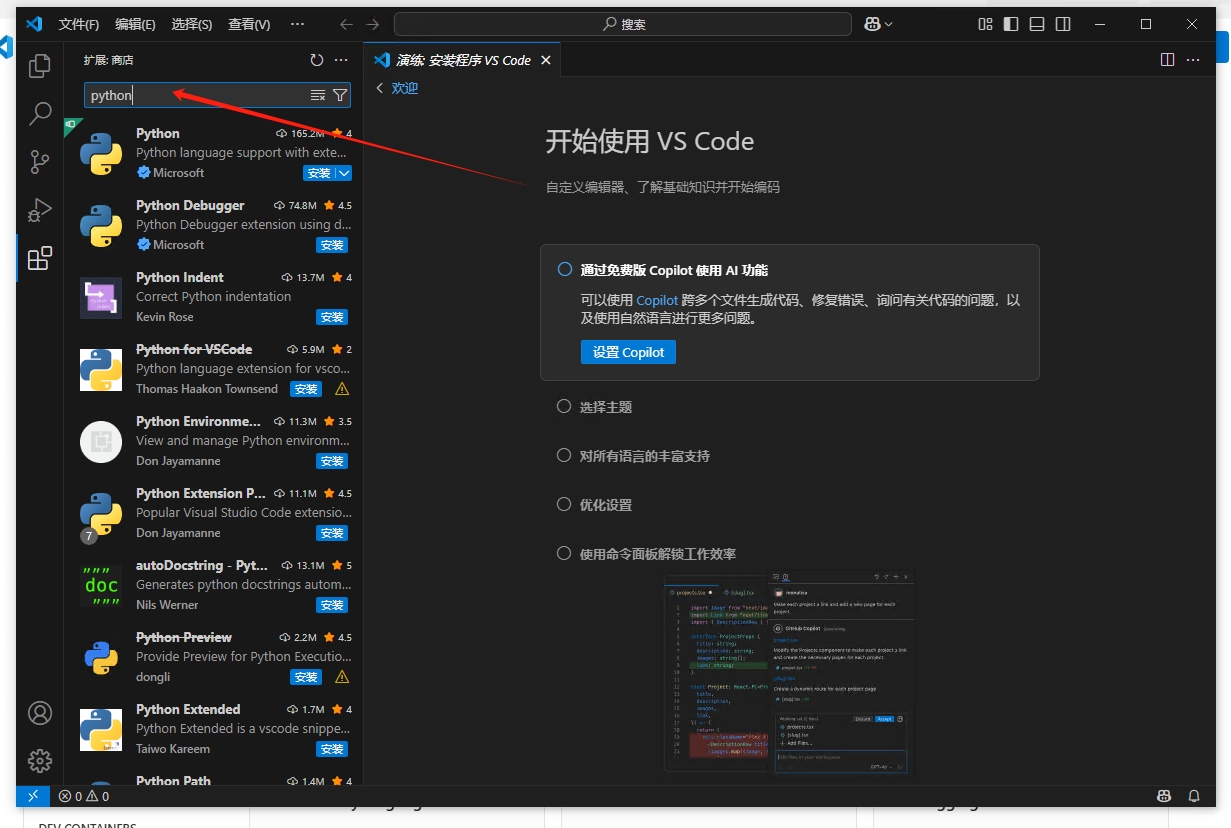
点击【安装】按钮进行安装
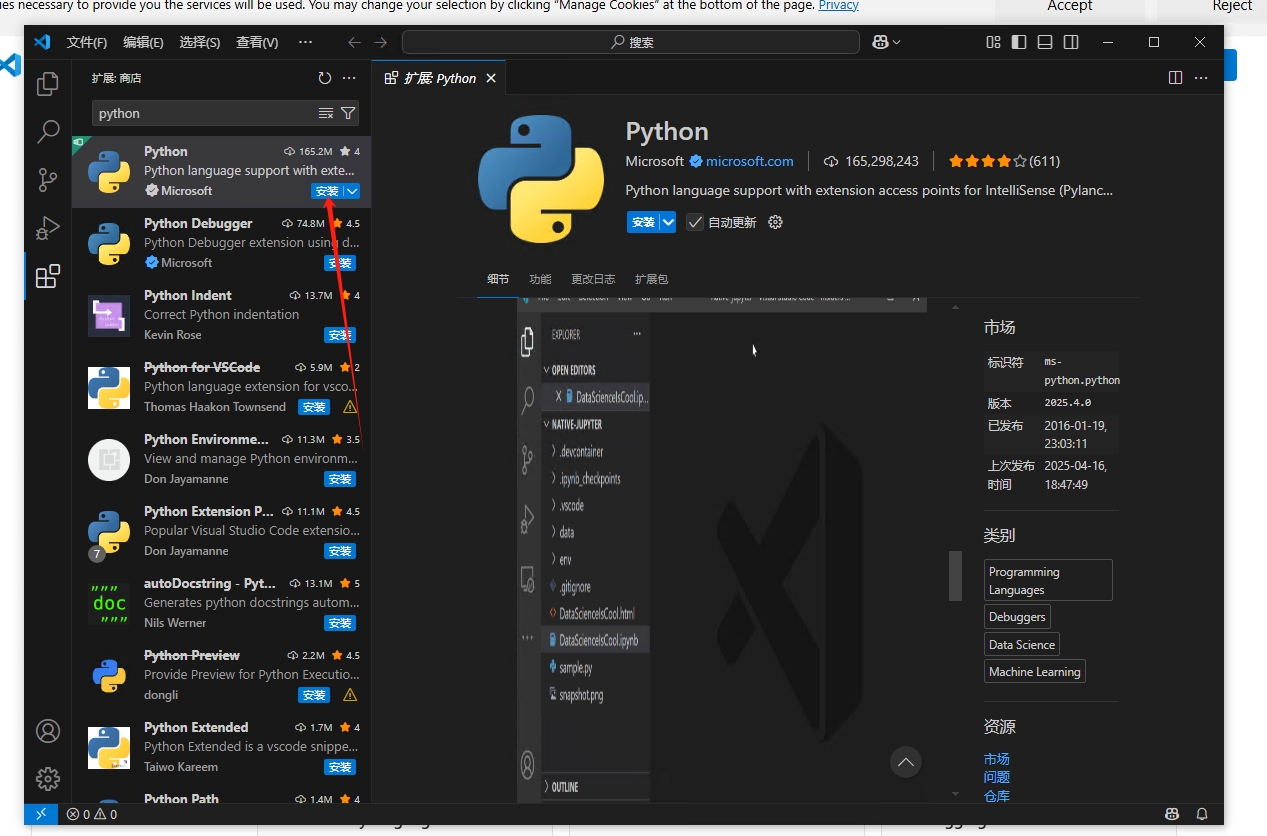
安装Robot Framework Support
继续搜索“Robot Framework Support”
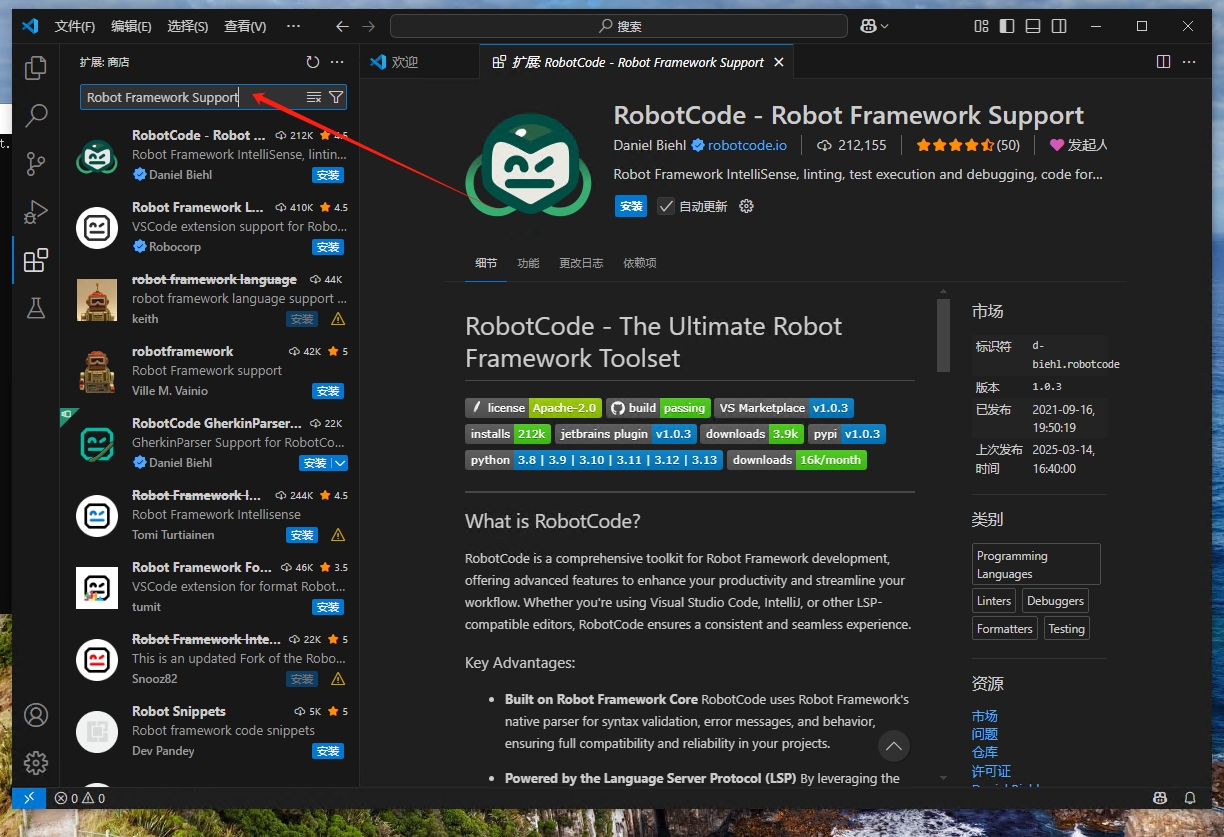
点击【安装】按钮安装
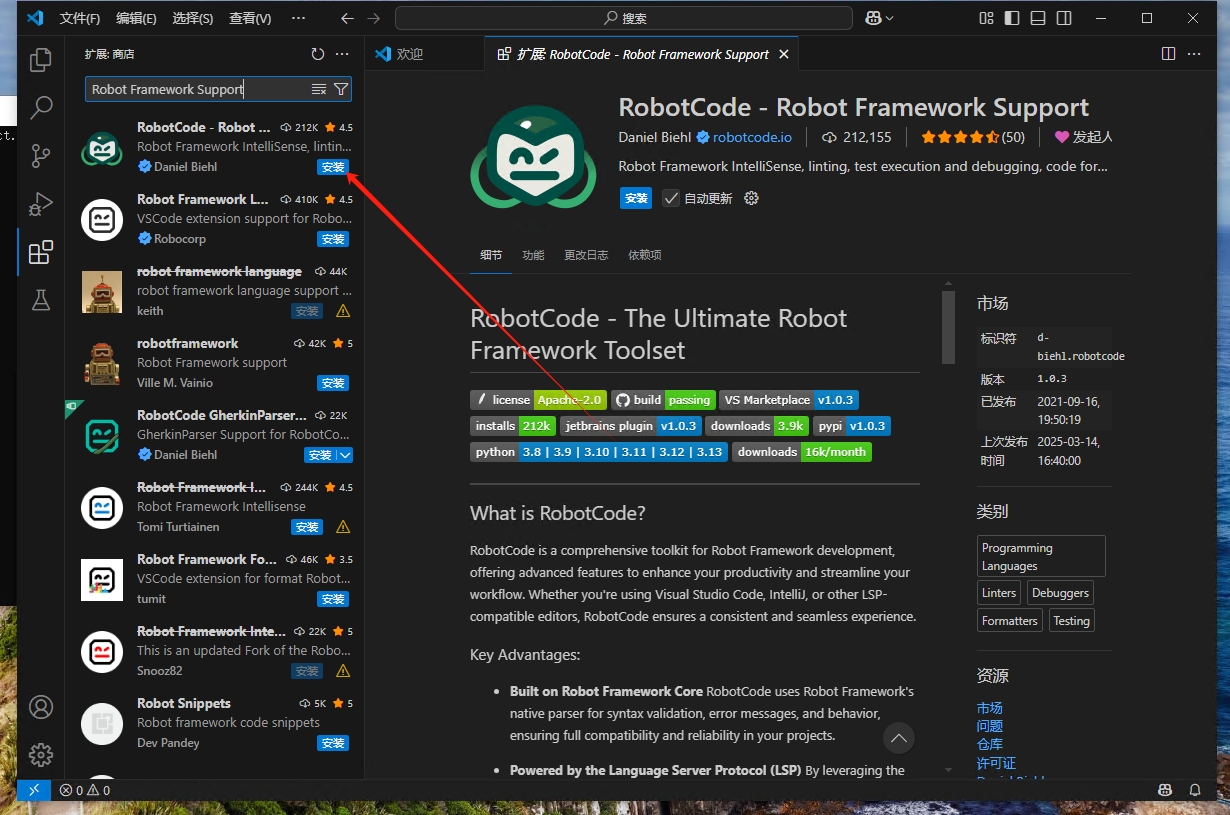
弹出是否信任发布者的一个弹窗,点击【信任发布者和安装】
安装web自动化支持库
web自动化使用的是seleniumlibrary这个库,我们使用pip命令下载安装
按键盘【开始】键+【R】建,输入cmd,回车打开命令行窗口
在命令行窗口中输入下面命令开始安装seleniumlibrary库
pip install robotframework-seleniumlibrary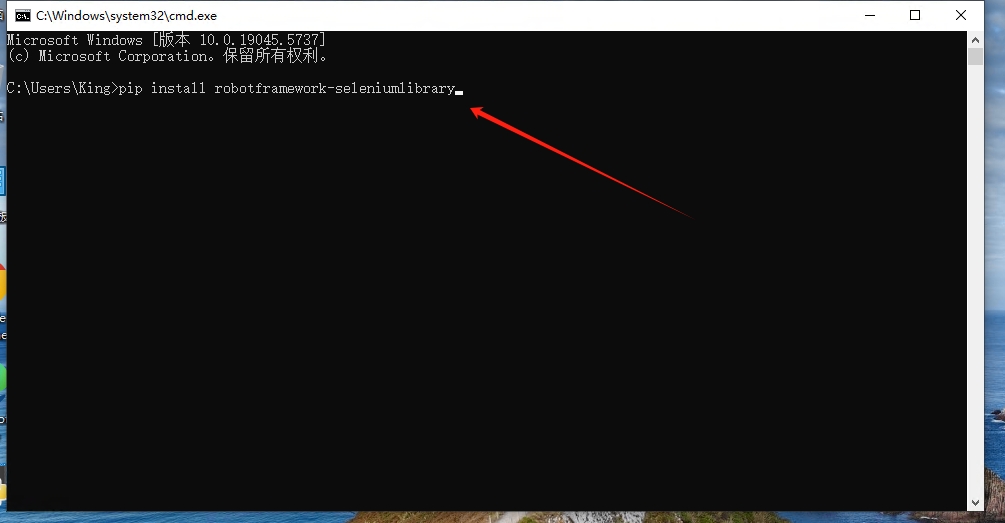
安装完成后输入pip list查看安装列表,看到seleniumlibrary库了就说明安装成功了

新建自动化项目
项目需求
打开百度,搜索Robot Framework
执行步骤
1、打开浏览器并打开https://www.baidu.com
2、在百度搜索框里面输入Robot Framework
3、点击百度的搜索按钮
新建文件夹
新的项目第一步肯定是新建文件夹呀
打开编辑器
点击左上角的文件图标
点击【打开文件夹】
也可以点击左上角的【文件】,然后点击【打开文件夹】
打开用来存储项目的文件夹,例如我在桌面上建了一个文件夹名字为脚本,然后所有的项目我都是放到脚本这个文件夹里面的,那么我就打开脚本这个文件夹,选中脚本这个文件夹后点击【选择文件夹】进行打开
点击脚本文件夹右边的新建文件夹图标
输入文件夹名称然后回车确定
在刚刚创建的文件夹下面在新建三个文件夹,分别是测试用例层、公共组件层和页面元素层
文件夹结构如下:
百度自动搜索
|____测试用例层
|____公共组件层
|____页面元素层之所以分这么多文件夹是因为我们需要把每个页面和每个功能分开,这样做方便我们自己后期维护,还有就是如果我们在一个项目里面需要调动很多重复的,那么这样也很方便,例如后期某个元素改ID了或者是路径变了,就可以很方便的在页面元素层找到,如果是小项目的话可以直接一个文件夹。
测试用例层的作用就是用来存储正式运行的脚本文件的,这个运行文件就是下面的公共组件层和页面元素层拼起来的,或者应该说这个运行文件是调用下面拿两个文件夹里面的文件来运行的。
公共组件层用来存储脚本的各个模块,例如打开浏览器
页面元素层用来存储网页页面信息,把这些区分开来后期维护需要修改的时候就直接到对应的模块或者页面去修改即可
选中刚刚新建的百度自动搜索这个文件夹,然后点击刚刚新建文件夹的那个图标
输入文件夹名称,然后回车
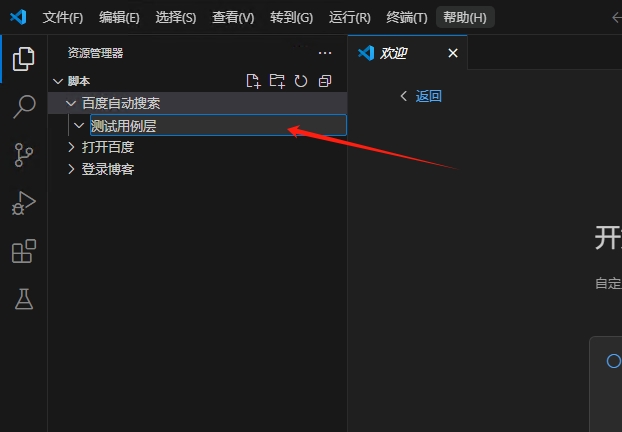
继续选中百度自动搜索这个文件夹,然后点击新建文件夹图标
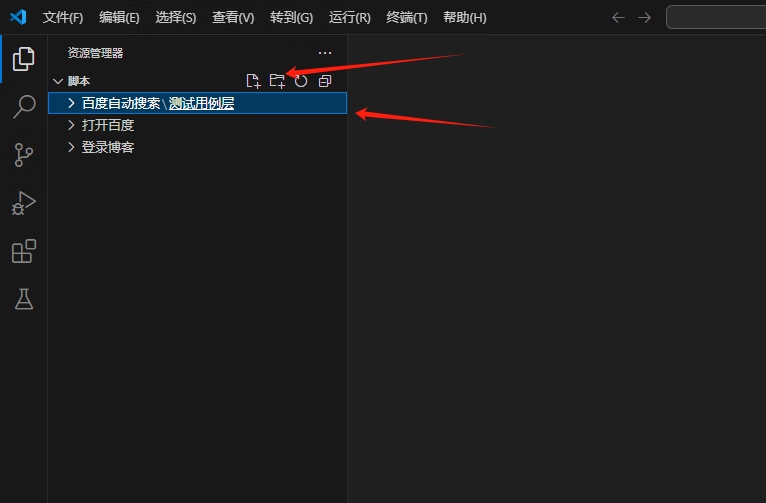
输入文件夹名称,然后回车保存
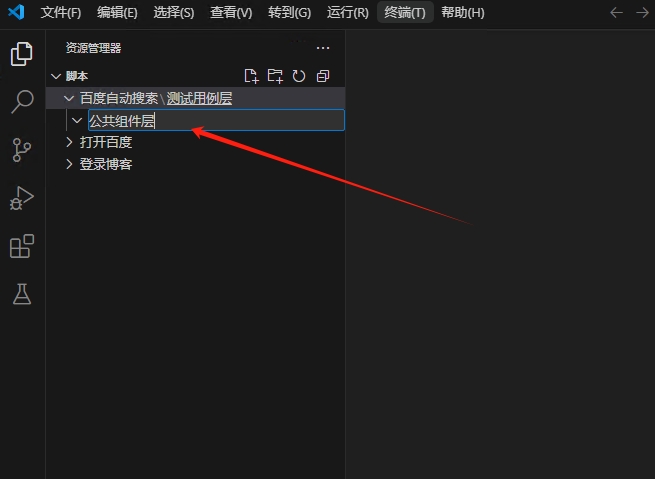
用同样的方法,选中百度自动搜索这个文件夹,然后在点击仙剑文件夹图标新建,注意每次新建文件或者是文件夹的时候,都要选中上一级文件夹。
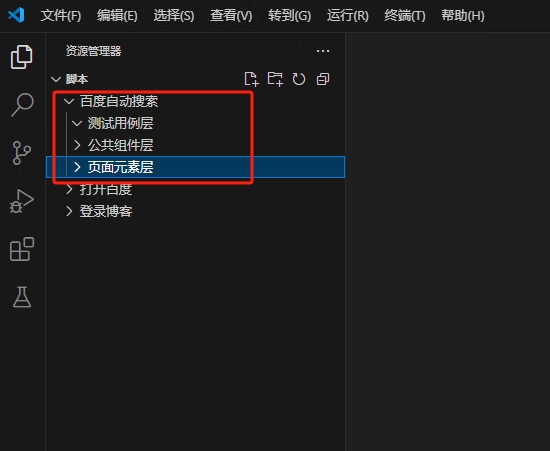
创建公共组件层的robot文件
robot文件组成介绍
Robot Framework的文件后缀名.robot,一个完成的可执行的robot文件一般有四个部分组成,分别是Settings、Variables、Test Cases、Keywords
Settings部分是设置部分,用于导入库、资源文件、变量文件等,还可以设置测试套件的文档、前置/后置条件等
Variables部分是变量部分,用来定义常量或参数,比如 URL、用户名、密码等
Test Cases部分是编写具体的测试步骤,是脚本的核心,每个测试用例就是一个流程,执行一系列关键字
Keywords部分是自定义关键字,你可以将多个关键字封装成一个复用的自定义关键字,更适合模块化、复用、保持代码整洁
新建打开浏览器.robot
首先新建一个名字为打开浏览器.robot的文件,这个文件用于打开指定的浏览器
右键公共组件层文件夹,点击【New Robot Framework File】
选择.robot文件
输入文件名
编辑打开浏览器.robot
新建好文件夹后就是开始编辑了,首先要编写这个文件的设置部分,把这个文件需要的库引入进去,这个是web自动化文件,所以需要引入SeleniumLibrary库
*** Settings *** #表示下面是这个文件的设置
Library SeleniumLibrary #引入SeleniumLibrary库,注意开头的S和中间的L是大写的,区分大小写,不能写错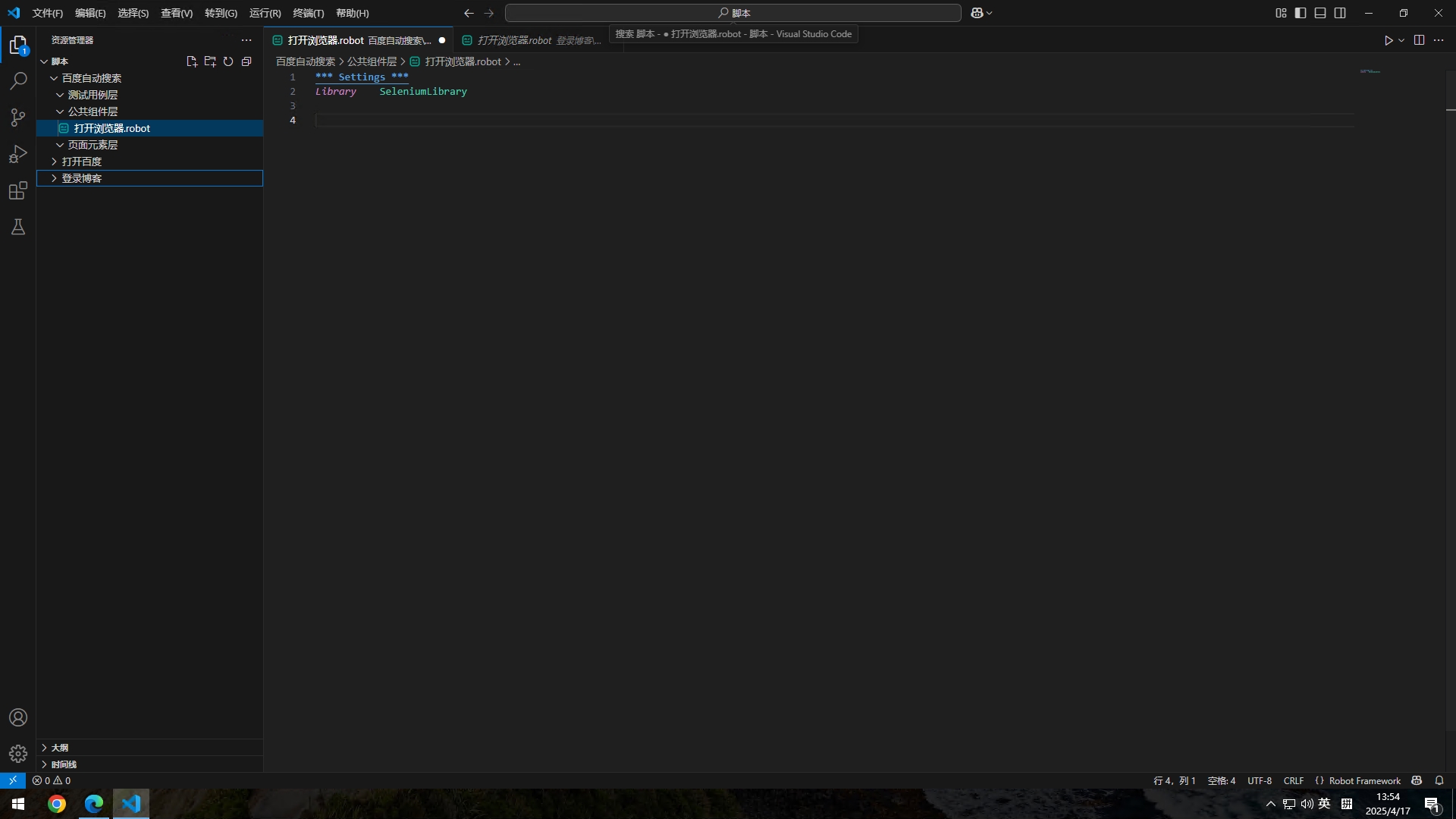
然后编辑关键字,在设置部分下面新建关键字部分
*** Keywords *** #表示下面是关键字部分
打开浏览器 #关键字部分名称
[Arguments] ${url} ${browser} #关键字变量
Open Browser ${url} ${browser} #引用关键字变量,Open Browser这个是系统内置的关键字了,意思是打开浏览器,后面带的第一参数是打开的网址,第二个参数是打开的浏览器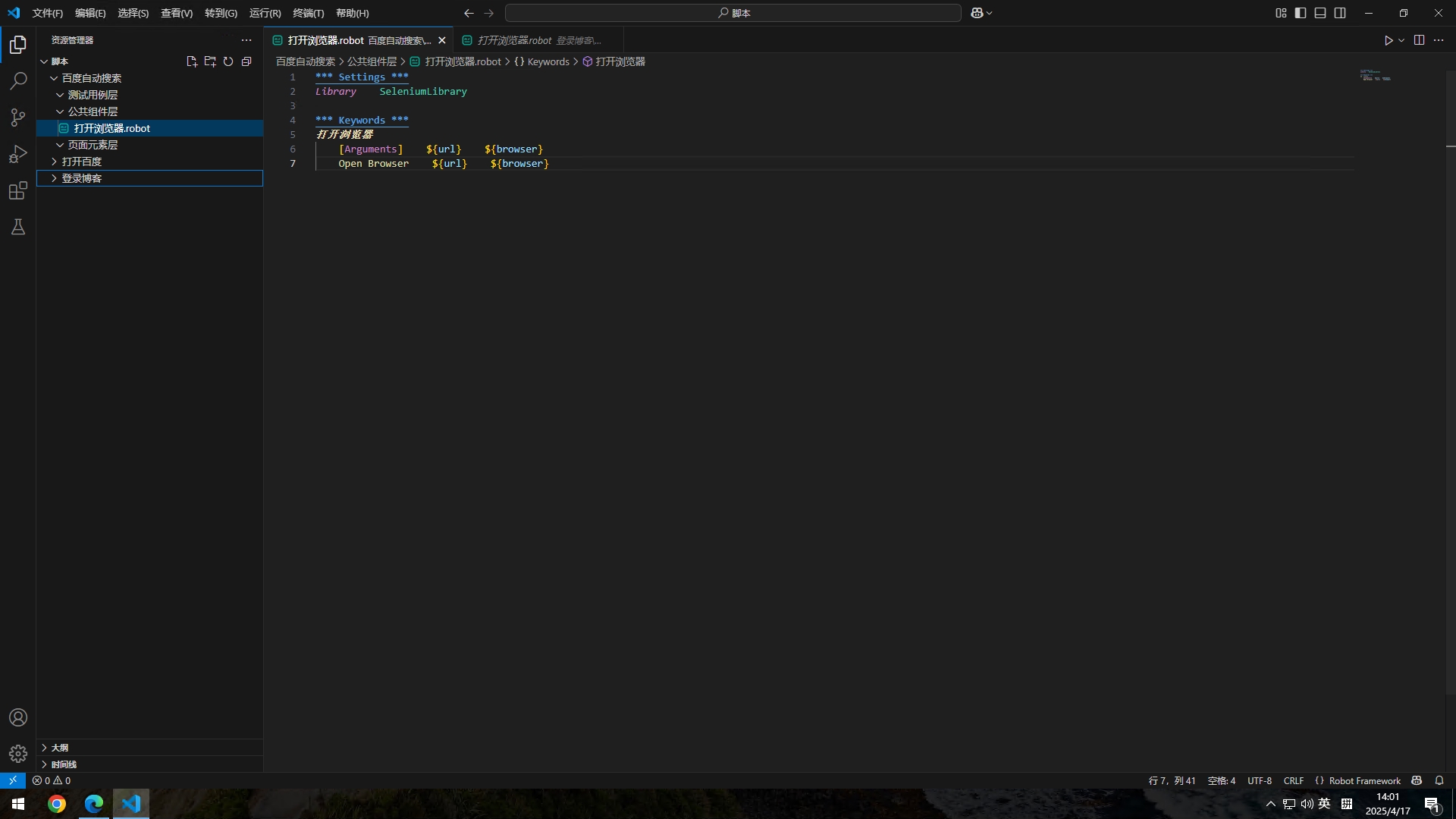
创建百度搜索页.robot
在页面元素层文件夹下面新建一个百度搜索页.robot文件
选中页面元素层文件夹,右键,点击【New Robot Framework File】
选择【.robot】文件
输入文件名,回车保存
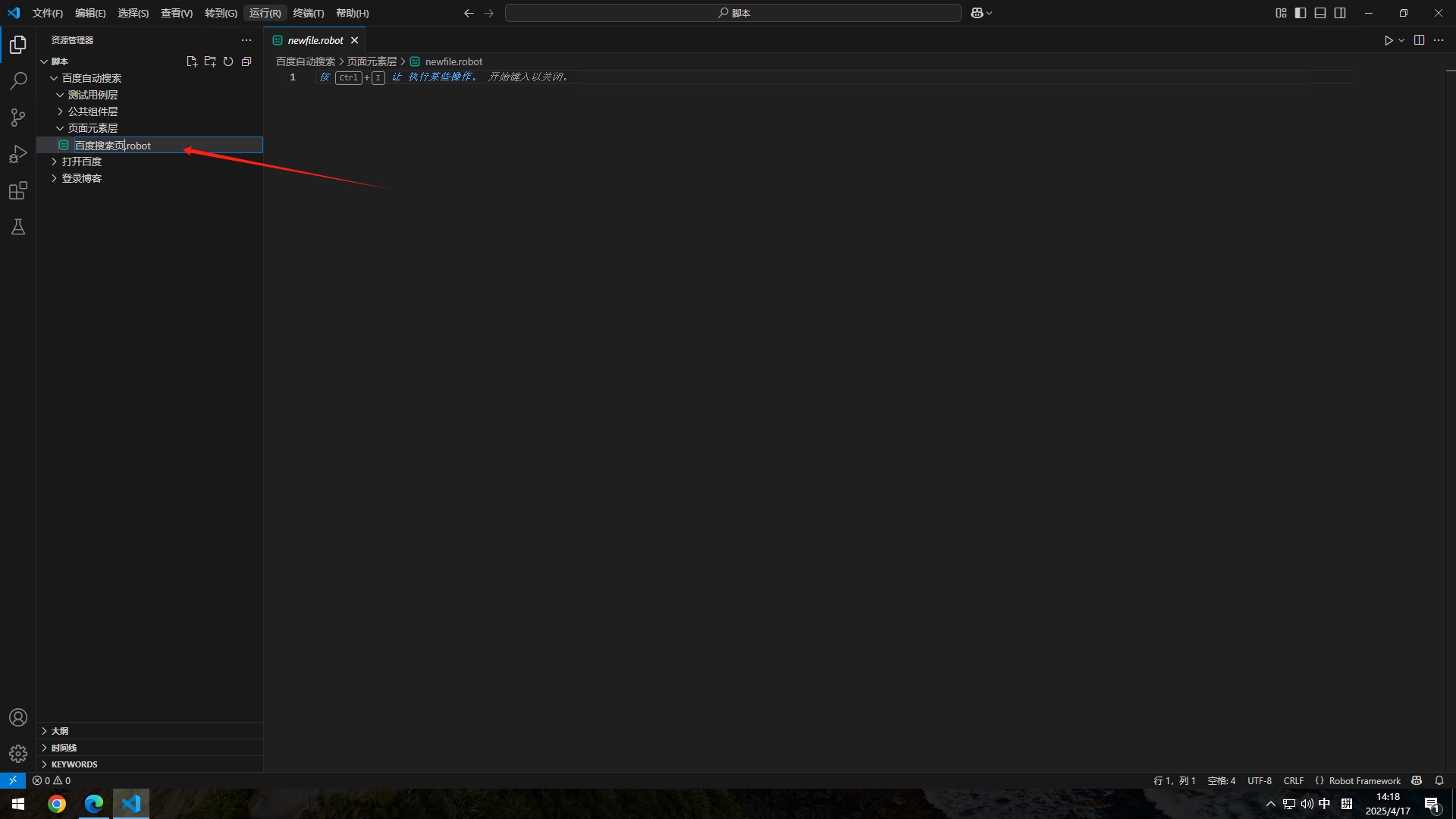
编辑百度搜索页.robot
和上面一样,先编辑我们的设置部分,引入我们的SeleniumLibrary库
*** Settings *** #下面是设置部分
Library SeleniumLibrary #导入SeleniumLibrary库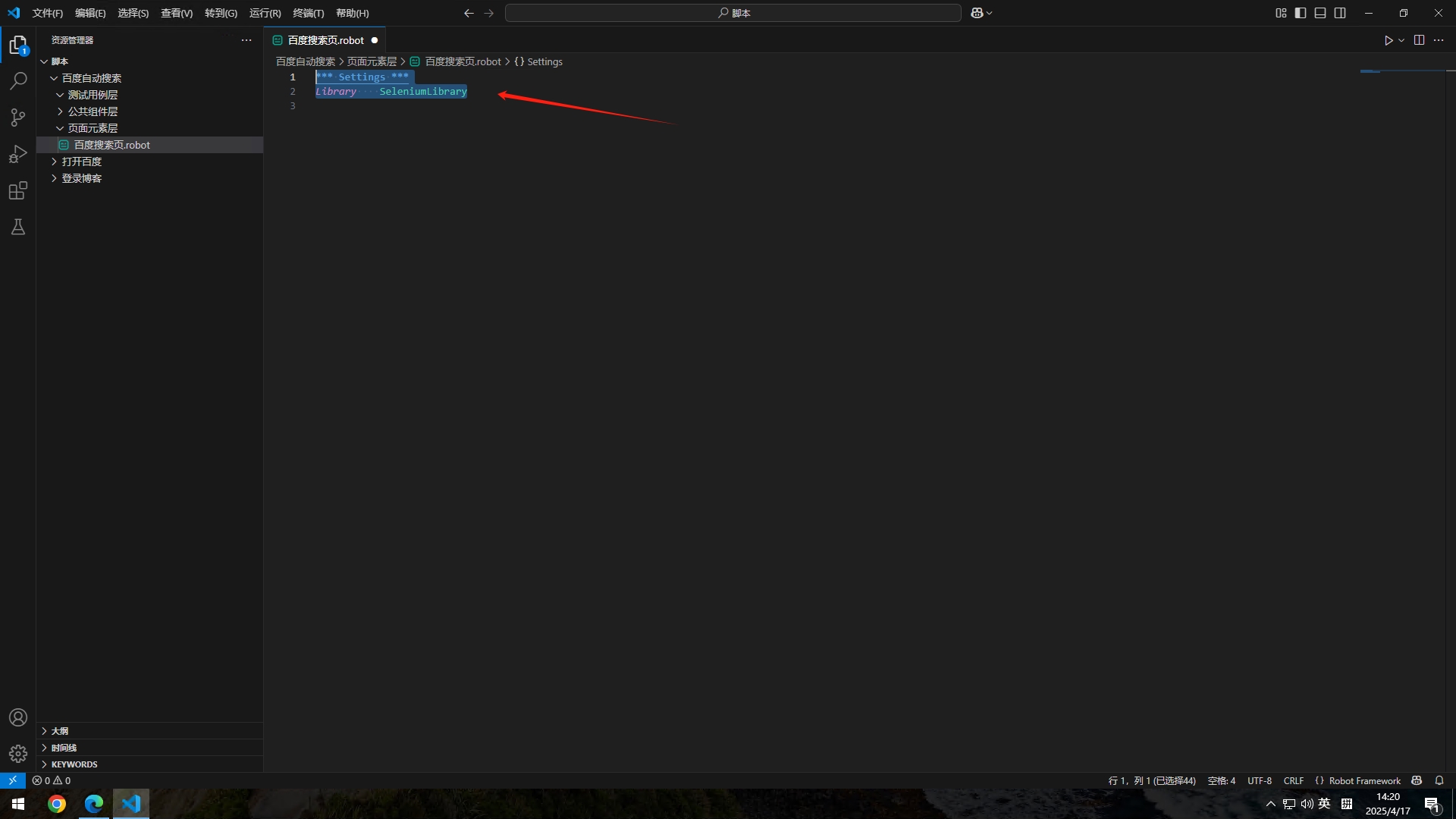
然后编辑关键字部分,这个页面我们需要实现的功能是在百度搜索框里面输入我们指定的内容,然后点击搜索按钮
首先创建一个关键字,名字为搜索内容,然后创建一个变量名字为text,然后在找到搜索框并把text输入进去,最后点击搜索按钮
*** Keywords *** #下面是自定义关键字部分
搜素内容 #关键字名称
[Arguments] ${text} #关键字变量
Input Text id=kw ${text} #关键字执行的操作,Input Text是内嵌关键字,意思是输入文本,id=kw是网页元素,${text}是变量,指定我们要搜素的内容
点击搜索按钮 #关键字名称
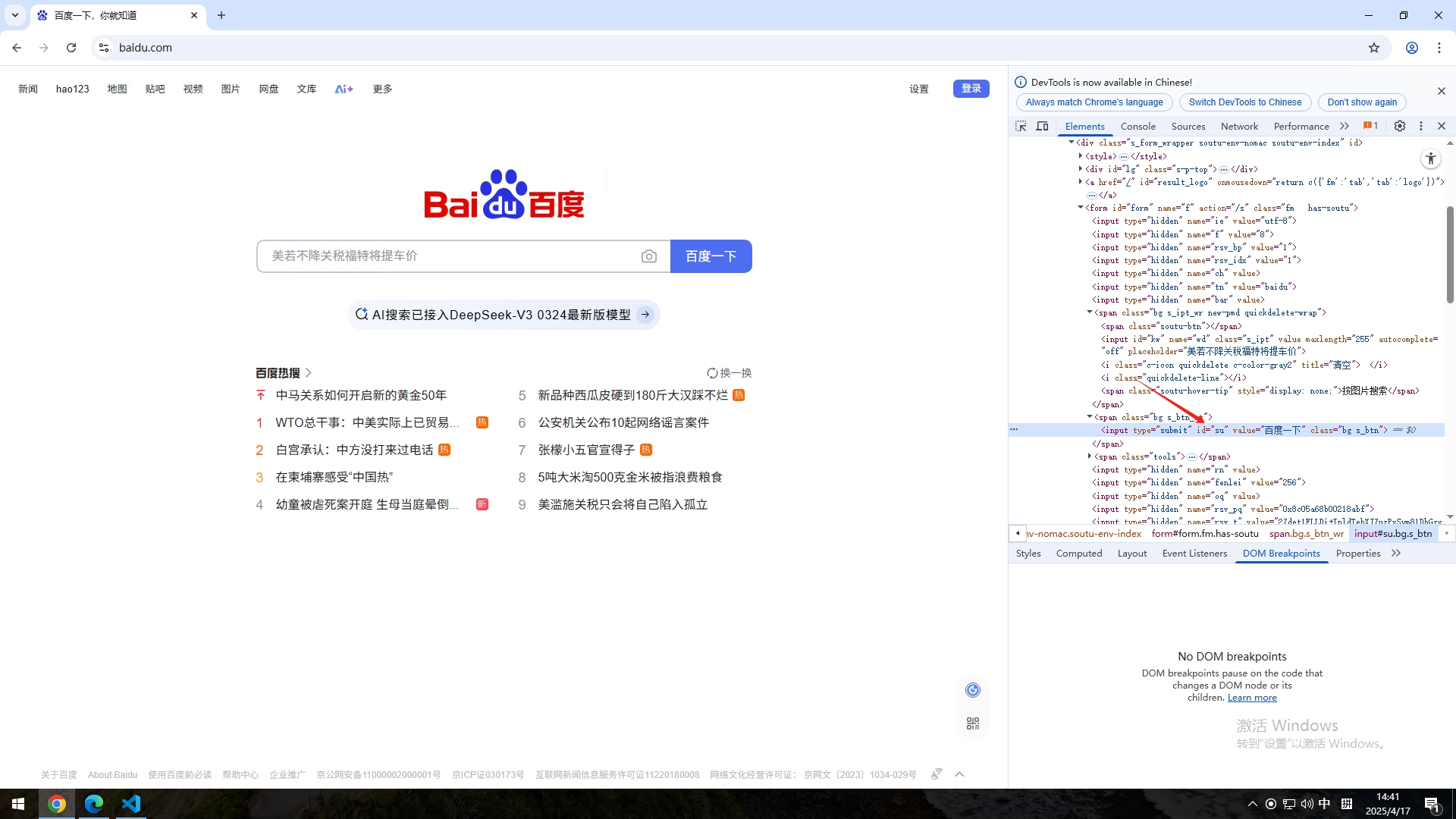
Click Button id=su #关键字执行的操作,Click Button是内嵌关键字,意思是单击按钮,id=su是网页元素如何获取网页元素呢,两种方法,这里先介绍第一种比较费时费力的方法,一百度搜索页为例子,打开百度搜索页,右键我们想要获取的元素,点击检查,例如我现在想要获取搜索框这个元素,需要定位搜索框这个元素,我右键搜索框,然后点击【检查】
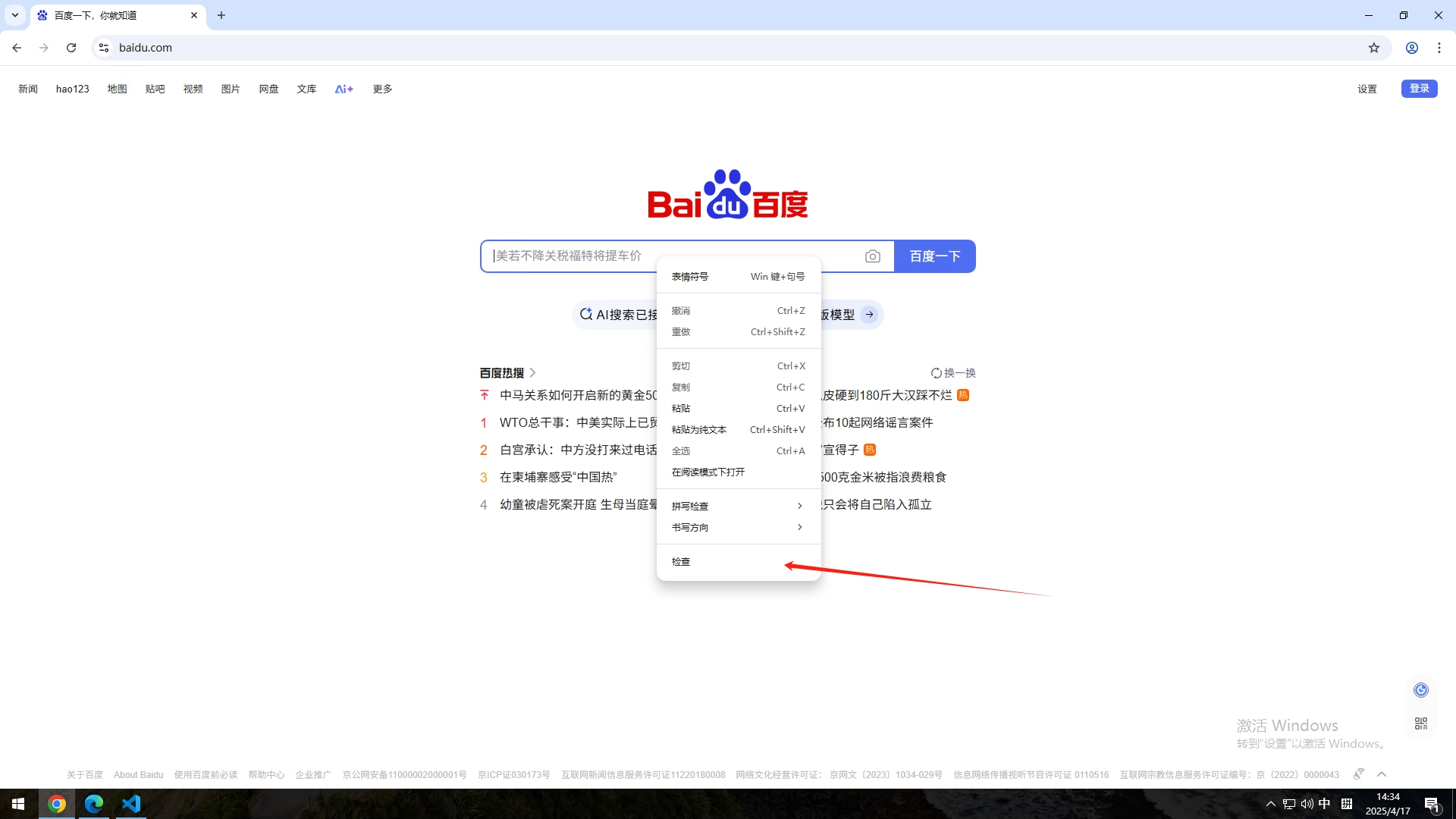
这时候浏览器打开调试窗口,我们检查的元素在右边会标注出来,把鼠标放到标注的地方,会发现左边的搜索框变颜色了,就说明是这一段代码了
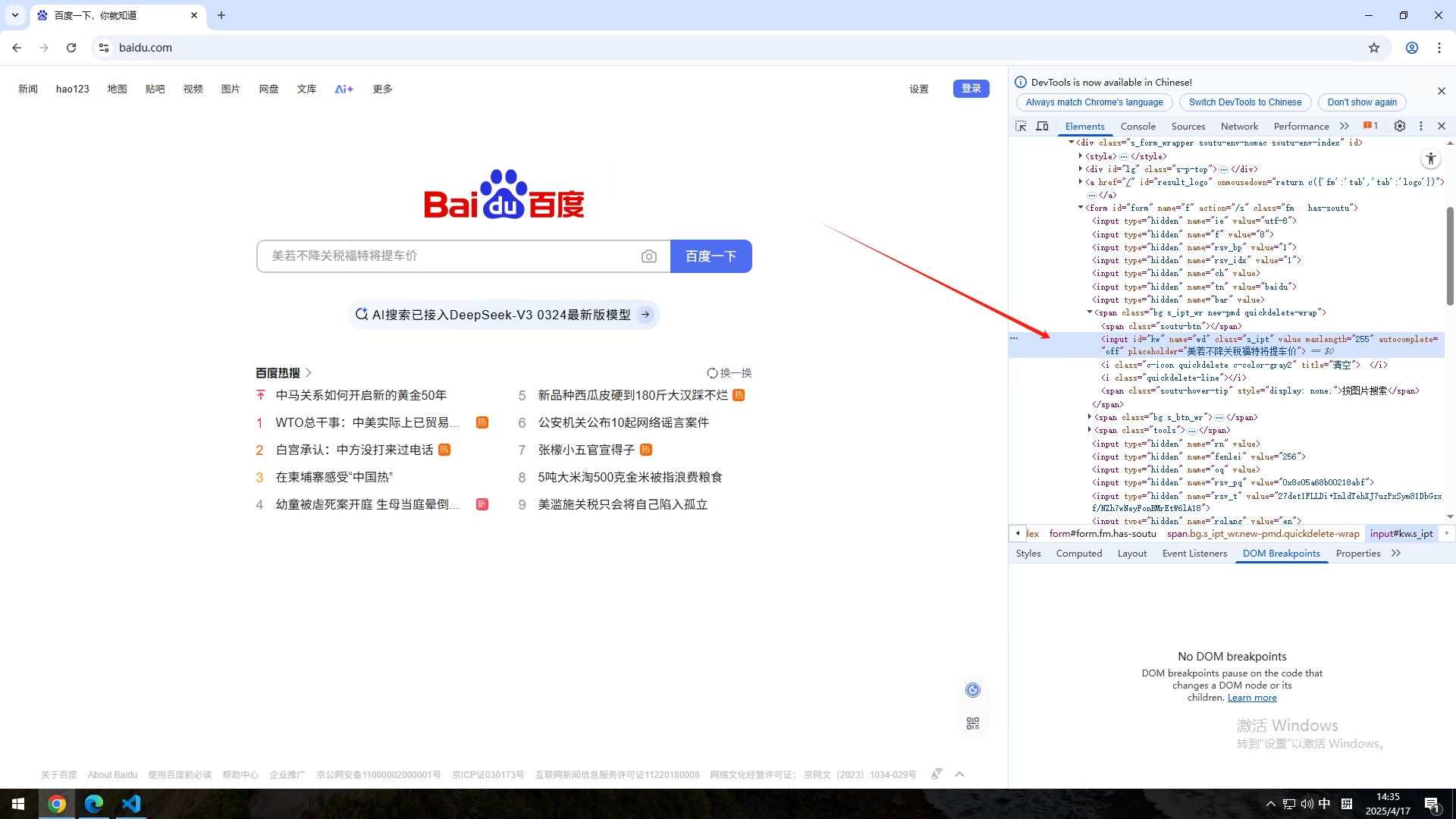
这时候我们只需要在代码里面找到id,name,class等字眼,因为这三个字都是用来定位元素的,但是有的元素不一定都有这三个字眼,可能只有其中一个,但是我们有其中一个就可以了,我这里使用的就是id,可以看到代码里面有id="kw",那这个就是输入框的id。
也可以使用路径来定位,这个最后在演示。
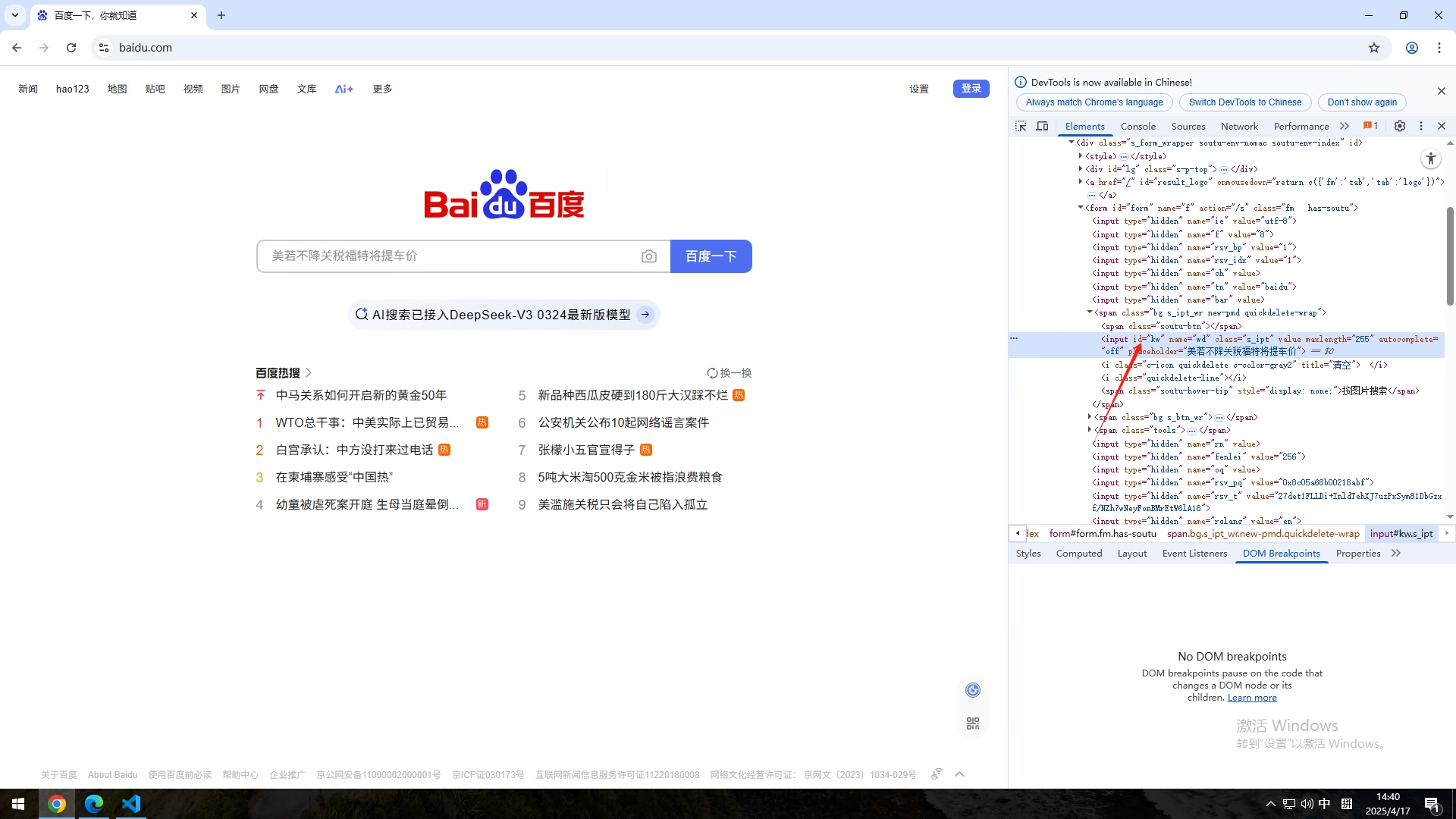
同理,右键搜索按钮,然后找到对应的代码,在代码里面找到id或者似乎class等可以用来定位的字眼
这个页面我们需要的功能已经写好了,下面是完整的代码
*** Settings ***
Library SeleniumLibrary
*** Keywords ***
搜素内容
[Arguments] ${text}
Input Text id=kw ${text}
点击搜索按钮
Click Button id=su
创建百度搜索.robot
公共组件层和页面元素层的文件已经编辑好了,当然,这个是一个小脚本,主要是用来让大家明白Robot Framework的编写结构和熟悉编写方式等等的,很简单的一个,如果是复杂的项目不可能只有这两个文件的
下面就是编写核心文件了
在测试用例层文件夹中新建一个百度搜索.robot文件,点击测试用例层,然后右键,点击【New Robot Framework File】
选择.robot
输入文件名,然后回车
编辑百度搜索.robot
首先也是编写设置部分,导入我们需要的库和刚刚编写的公共组件层以及页面元素层的文件
*** Settings *** #下面是设置部分
Library SeleniumLibrary #导入SeleniumLibrary
Resource ../公共组件层/打开浏览器.robot #导入刚刚编写的打开浏览器.robot
Resource ../页面元素层/百度搜索页.robot #导入刚刚编写的百度搜索页.robot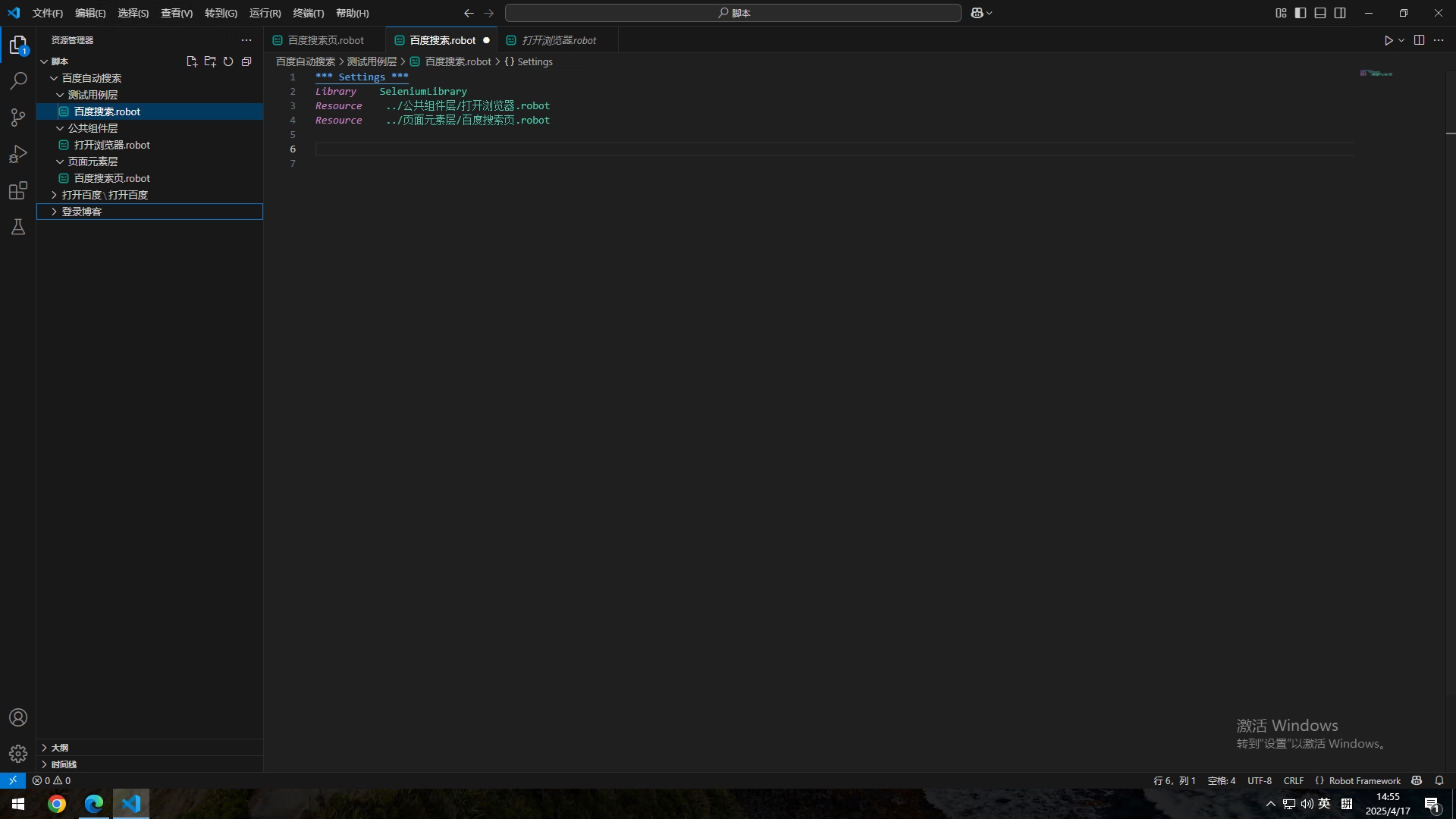
然后编写核心部分
*** Test Cases *** #下面是测试用例部分
百度搜索 #测试用例名称
打开浏览器 https://www.baidu.com chrom #打开浏览器是我们刚刚定义的关键字,关键字里面有两个变量,一个是url,另外一个browser 打开浏览器后面的两个参数就是对这两个变量的赋值,如果有三个变量那么打开浏览器后面就要有三个参数
搜索内容 Robot Framework #搜索内容这个也是刚刚我们在页面元素层定义的关键字,后面就是我们刚刚定义text这个变量的复制
点击搜索按钮 #点击搜索按钮这个也是我们在页面元素层里面定义的关键字,这个关键字里面没有变量,只有指定单击id=su这个元素。下面是完整的代码
*** Settings ***
Library SeleniumLibrary
Resource ../公共组件层/打开浏览器.robot
Resource ../页面元素层/百度搜索页.robot
*** Test Cases ***
百度搜索
打开浏览器 https://www.baidu.com chrome
搜索内容 Robot Framework
点击搜索按钮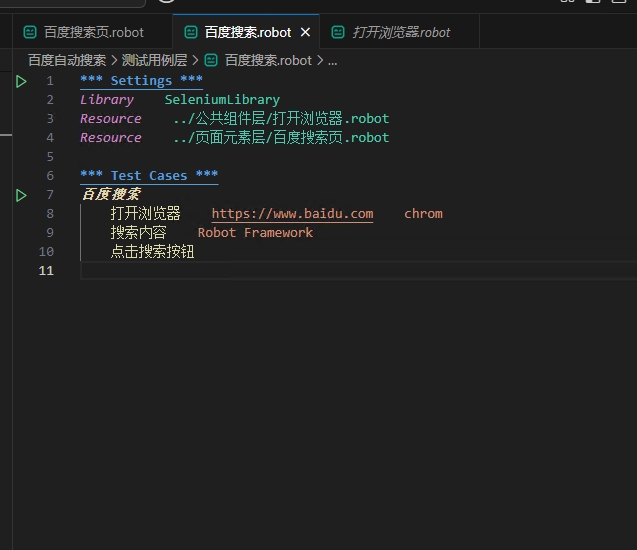
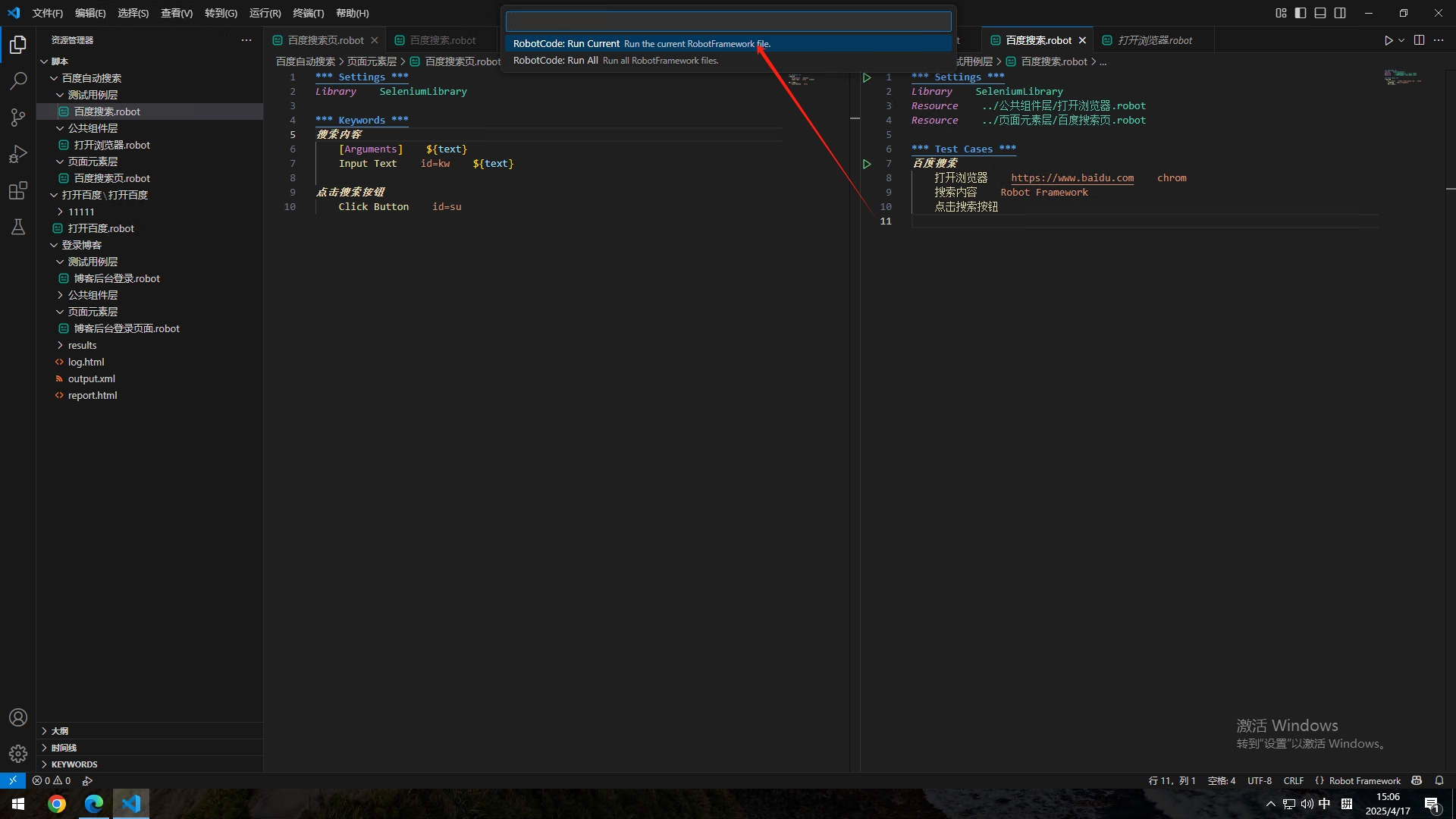
这样这个小脚本就编写完成了,接下来就可以测试了,按F5
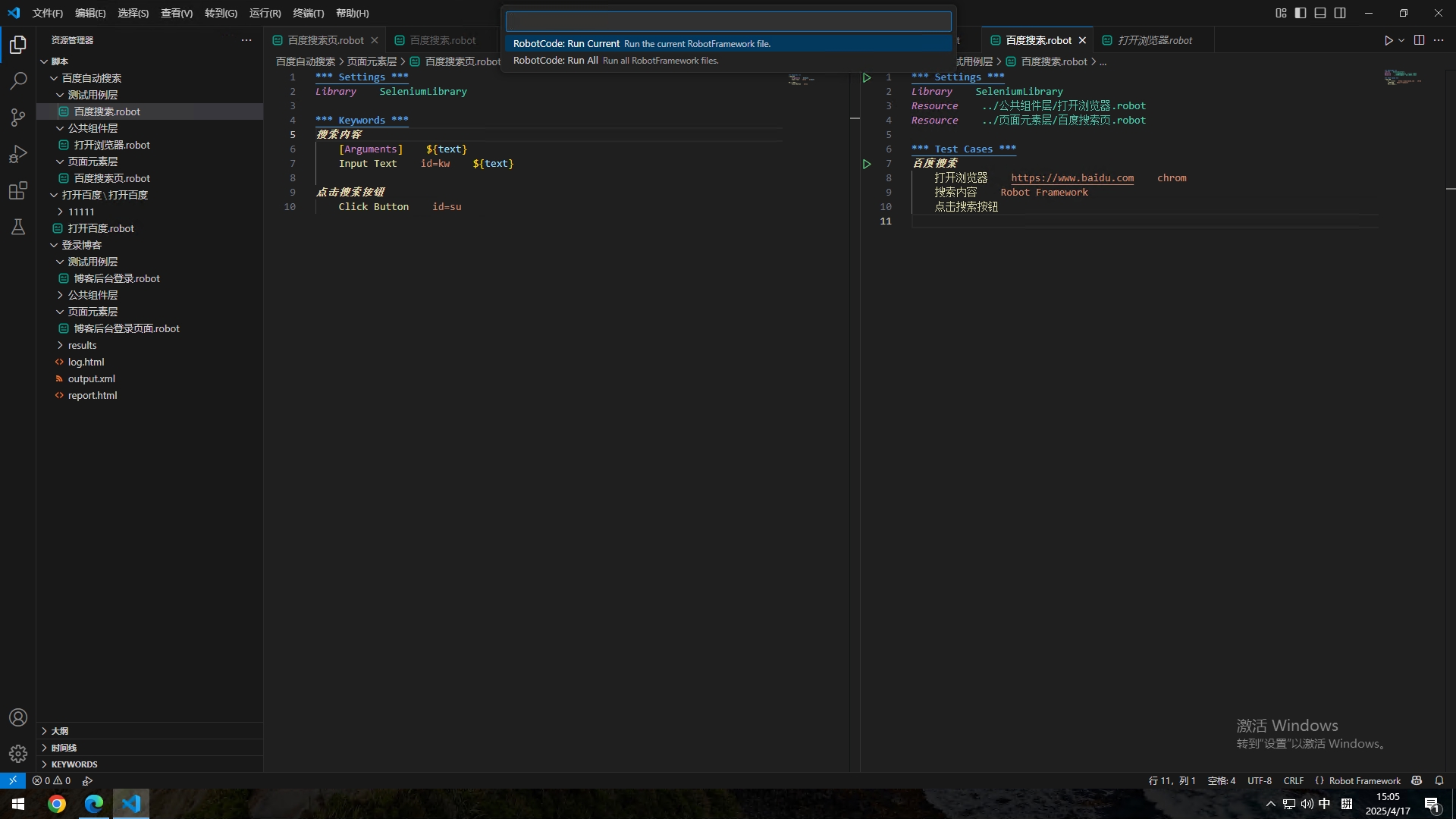
点击第一个【RobotCode:Run Current......】
总结
这个文章可能有的小伙伴看的云里雾里的,但是代码这个东西有时候很抽象,之意会不可言传,按照上面的实操两边之后慢慢琢磨就明白了
获取元素
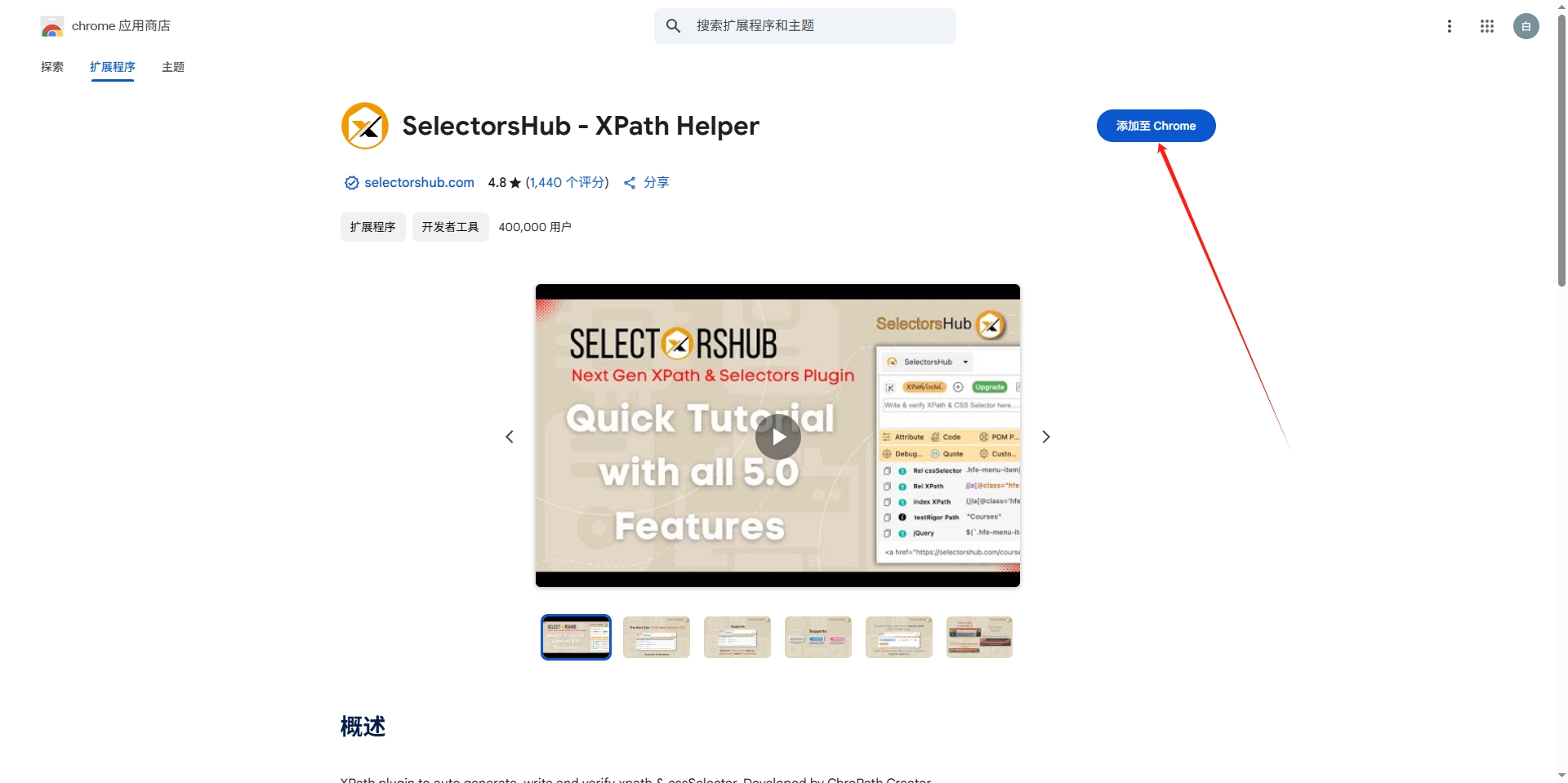
上面说了一种元素定位方法,比较笨的,费时费力的,其实元素定位有插件的,以谷歌浏览器为例,可以使用SelectorsHub - XPath Helper,但是这个插件唯一不好的就是会加载广告,但是又没有找打比这个更好用的了
如果你的浏览器可以访问谷歌应用商店,直接在拓展中心里面搜索安装即可
如果不能访问可以从本站下载离线包进行安装,离线包安装需要打开开发者模式,这里不详细讲解,可以自行百度一下
本站下载地址:点击下载
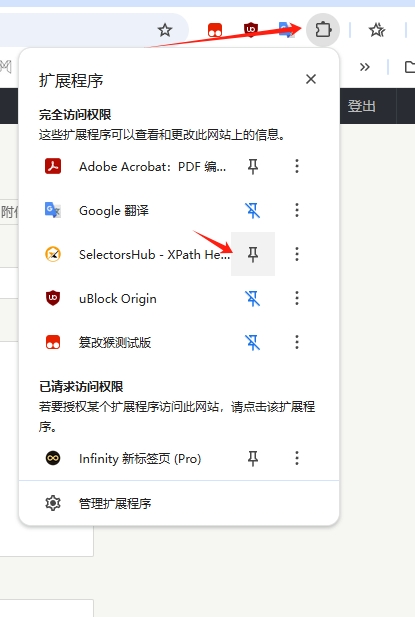
安装好后,在拓展程序里面把它固定到浏览器顶部
在需要获取元素的网页点击插件
点击插件左上角的小箭头
然后点击需要获取的元素
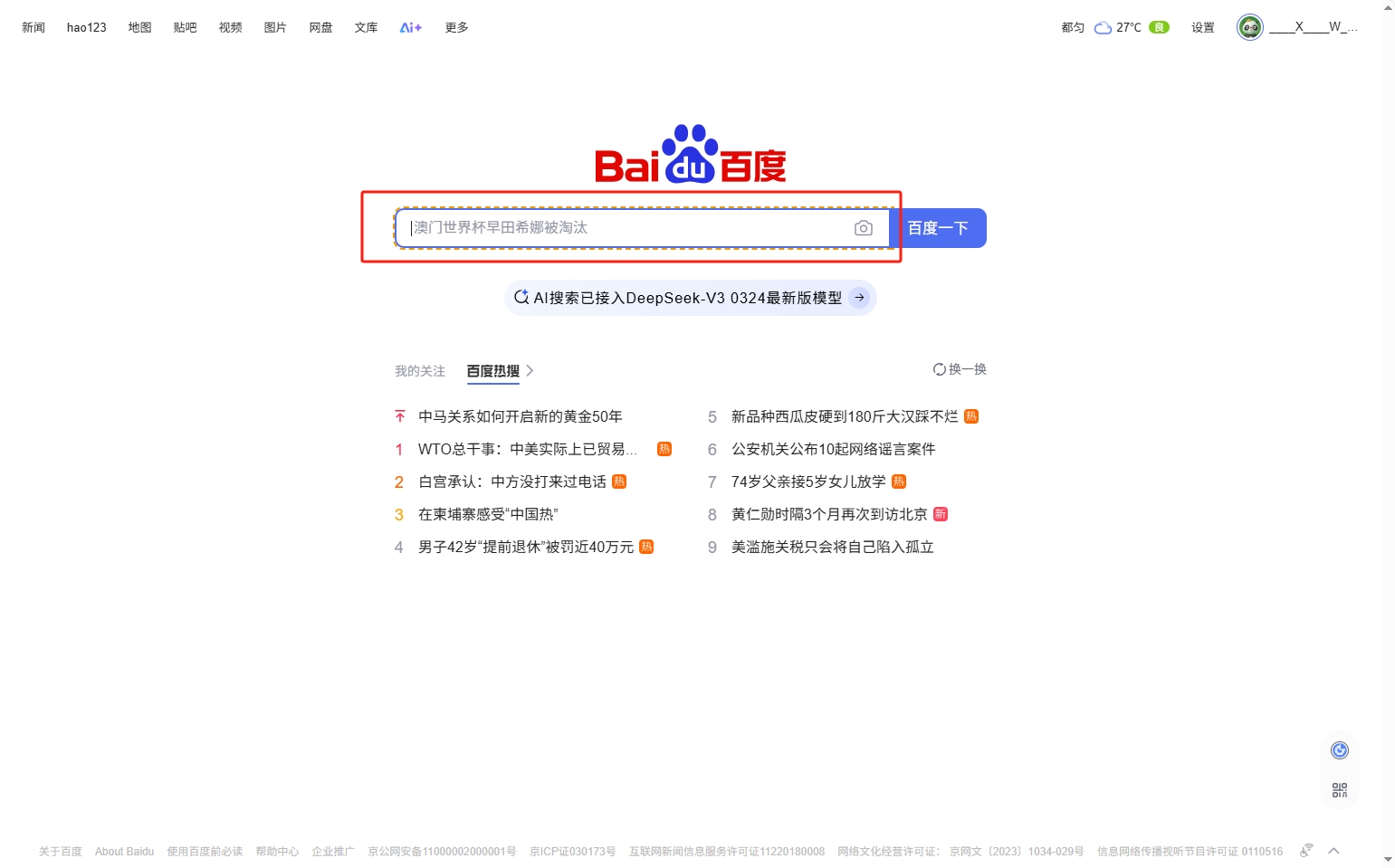
在右边就可以看到元素的id,路径之类的了
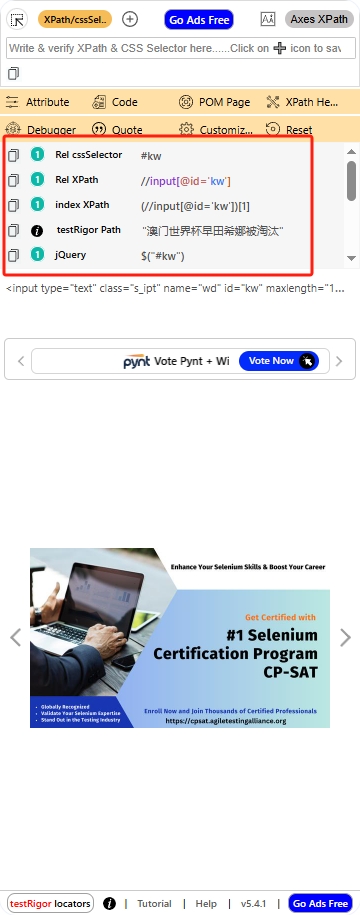
Robot Framework元素定位方式
Robot Framework中定位元素可以使用id,name,class,xpath等,详细的可以看下面表格
| 定位方式 | 示例 | 说明 |
|---|---|---|
| id | id=username | 根据元素的 id |
| name | name=email | 根据元素的 name |
| xpath | xpath=//input[@type='text'] | 使用 XPath 表达式 |
| css | css=input.login | 使用 CSS 选择器 |
| class | class=btn-primary | 根据元素的 class 名 |
| tag | tag=input | 根据 HTML 标签名 |
| link | link=Forgot Password? | 根据链接文本(超链接) |
| partial link | partial link=Forgot | 根据部分链接文本 |
| dom | dom=document.querySelector("div.class") | 通过 JS 访问 DOM(较少用) |
